Training Data¶
Training data can be created in a variety of ways, but the algorithm expects a Feature Collection of points with unique land cover labels identified with a ‘label’ attribute. For example, forests can have a ‘label’ attribute of 1, agriculture as 2, and so on. One simple method to develop training data is to simply use the data on the Google Earth Engine and creating a Feature Collection for each land cover.
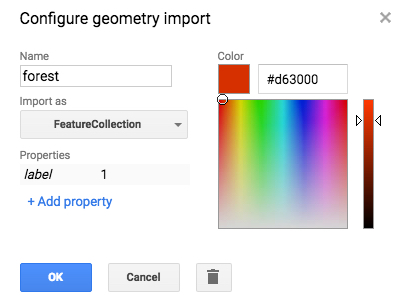
- While in the Earth Engine, navigate to Geometry Imports -> + new layer.
- In the layer configuration, given the layer a name, set the type to FeatureCollection, and give it a ‘label’ property with a unique integer identifier.
- Using the data available on the Earth Engine, such as Landsat, Sentinel-2, and the high resolution background imagery, add training points that correspond to a certain time period. For example, all of the training points could correspond to the land cover from 2012-2014. See the official Earth Engine tutorials for information on finding and displaying Image Collections.
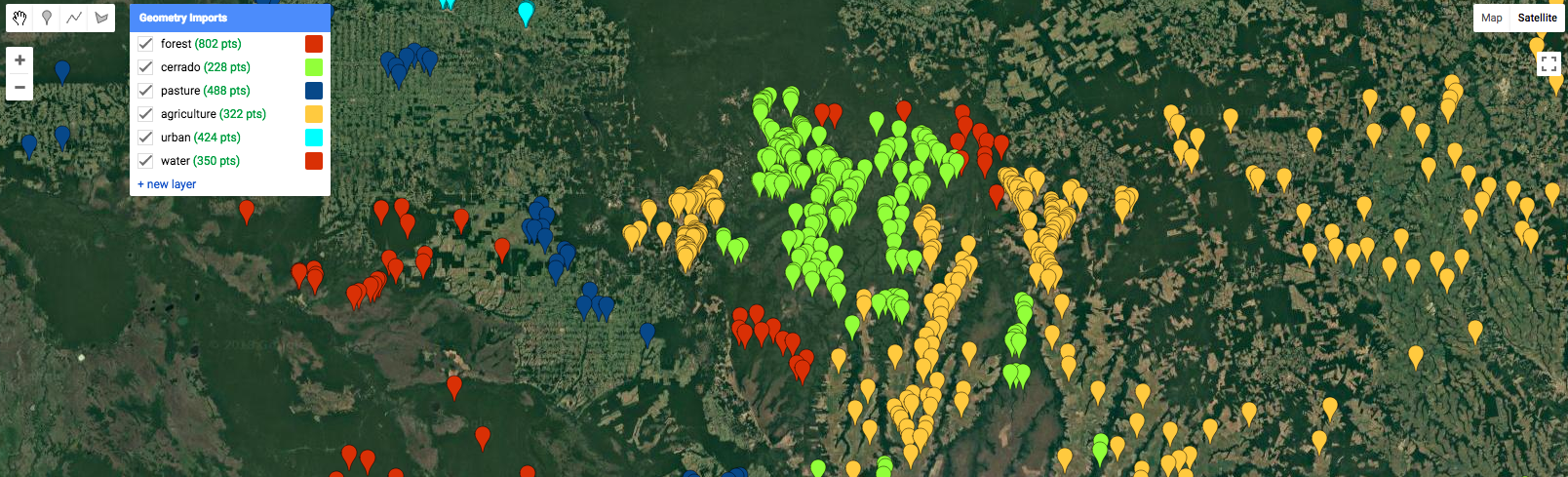
- Create training data for all land covers in the study region. The land covers are necessary to differentiate between forest conversion and a disturbance that does not result in a change in land cover.
- The training features can be combined with the ‘merge’ method. For example, assuming ‘forest’, ‘pasture’, ‘agriculture’, ‘urban’, and ‘water’ all represent Feature Collections:
var training = forest.merge(pasture)
.merge(agriculture)
.merge(urban)
.merge(water)
- The outputs should then be saved as an Earth Engine asset.
Export.table.toAsset({
collection: training,
description: 'sample',
assetId: 'sample'
})